Match-and-Fuse generalizes to sketched inputs, enabling controlled storyboard generation.
We present Match-and-Fuse – a zero-shot, training-free method for consistent controlled generation of unstructured image sets – collections that share a common visual element, yet differ in viewpoint, time of capture, and surrounding content. Unlike existing methods that operate on individual images or densely sampled videos, our framework performs set-to-set generation: given a source set and user prompts, it produces a new set that preserves cross-image consistency of shared content. Our key idea is to model the task as a graph, where each node corresponds to an image and each edge triggers a joint generation of image pairs. This formulation consolidates all pairwise generations into a unified framework, enforcing their local consistency while ensuring global coherence across the entire set. This is achieved by fusing internal features across image pairs, guided by dense input correspondences, without requiring masks or manual supervision. It also allows us to leverage an emergent prior in text‑to‑image models that encourages coherent generation when multiple views share a single canvas. Match-and-Fuse achieves state-of-the-art consistency and visual quality, and unlocks new capabilities for content creation from image collections.
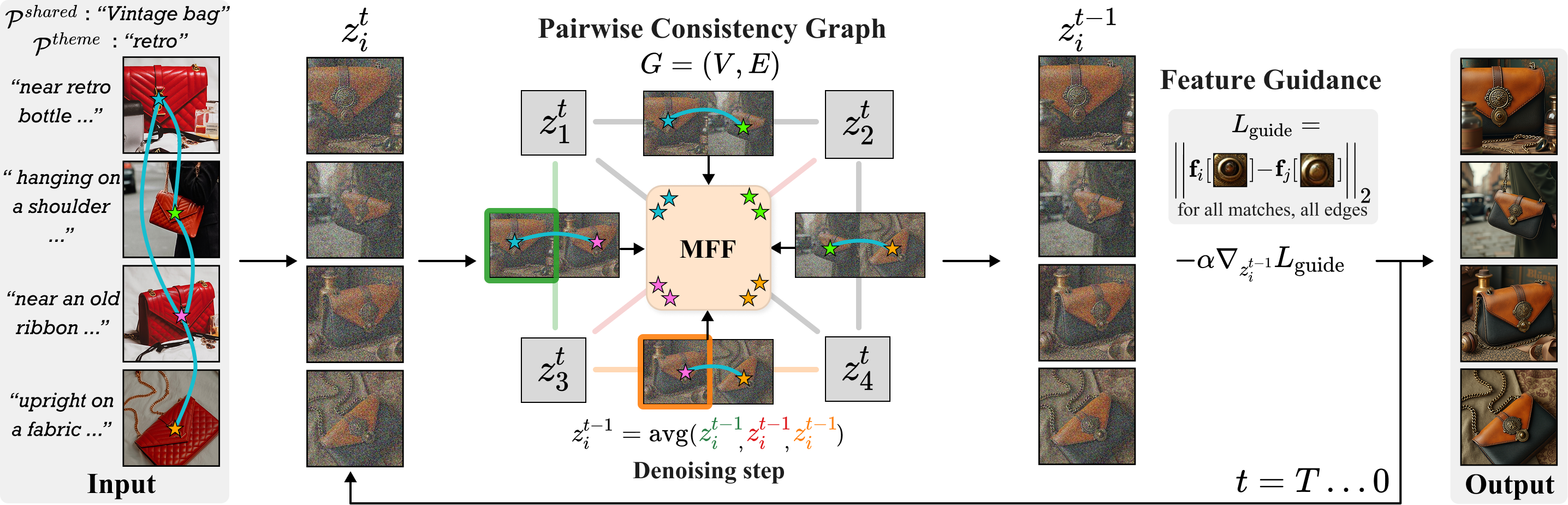
The input to our method is an unstructured set of \(N\) images along with user-provided prompts: \(\mathcal{P}^{shared}\) and \(\mathcal{P}^{theme}\), describing the target shared content and general style or theme, respectively. Our method outputs \(N\) images that preserve the source semantic layout while ensuring visual consistency across shared elements.
We build on a pre-trained, frozen, depth-conditioned T2I model. Although designed for single-image generation, these models have been shown to produce image grids when prompted with joint layouts (e.g., "Side-by-side views of..."), establishing cross-image relationships as demonstrated in recent work [1, 2]. However, this emerged capability, which we refer to as the grid prior, exhibits several key limitations: (i) it provides only partial consistency in appearance, shape, and semantics; (ii) the consistency deteriorates rapidly as more images are composed; and (iii) generating a single canvas is bounded by the model’s native resolution, limiting scalability.
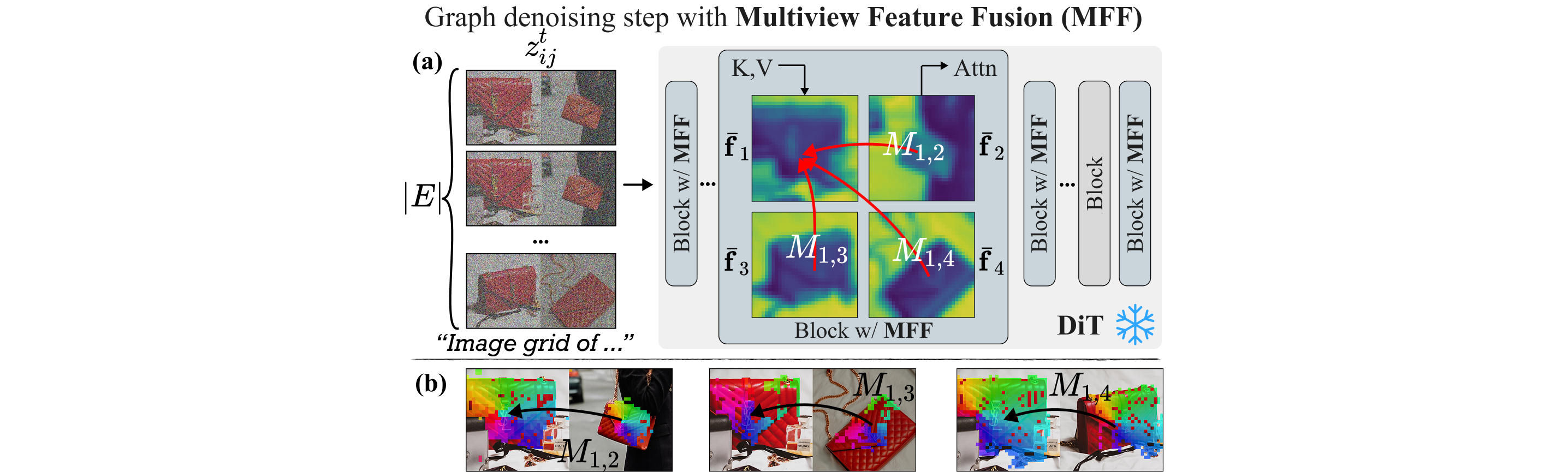
Our method leverages the grid prior while overcoming its core limitations. Specifically, we model the image set as a Pairwise Consistency Graph, comprising of all possible two-image grid generations. This allows us to exploit the strong inductive bias of the grid prior, while eliminating its scale limitation. To enhance visual consistency both within each image grid and across grids, we perform joint feature manipulation across all pairwise generations. To this end, we utilize dense 2D correspondences from the source set to automatically identify shared regions – without requiring object masks – and enforce fine-grained alignment. We find that feature-space similarity along these matches correlates strongly with visual coherence, motivating the use of Multiview Feature Fusion. We further refine details via Feature Guidance, using a feature-matching objective.
Match-and-Fuse generates consistent content of rigid and non-rigid shared elements, single and multi-subject, with shared or varying background, preserving fine-grained consistency in textures, small details, and typography. Notably, it can generate consistent long sequences.















































































































Match-and-Fuse generalizes to sketched inputs, enabling controlled storyboard generation.















































Match-and-Fuse enables consistent, localized editing without \(\mathcal{P}^{theme}\), achieved through integration with FlowEdit [3].














































































































































[1] Lianghua Huang, Wei Wang, Zhi-Fan Wu, Yupeng Shi, Huanzhang Dou, Chen Liang, Yutong Feng, Yu Liu, and Jingren Zhou. In-context lora for diffusion transformers. 2024. 2, 6, 7, 11
[2] Chaehun Shin, Jooyoung Choi, Heeseung Kim, and Sungroh Yoon. Large-scale text-to-image model with inpainting is a zero-shot subject-driven image generator.
[3] Vladimir Kulikov, Matan Kleiner, Inbar Huberman-Spiegelglas, and Tomer Michaeli. Flowedit: Inversion-free text-based editing using pre-trained flow models. arXiv preprint arXiv:2412.08629, 2024. 8
@inproceedings{matchandfuse2026,
title={Match-and-Fuse: Consistent Generation from Unstructured Image Sets},
author={Feingold, Kate and Kaduri, Omri and Dekel, Tali},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2026}
}